Situación actual de los modelos fine-tuned
Tras el lanzamiento de LLaMA v1, el primer Large Language Model (LLM) open source que podía hacer frente a los grandes modelos propietarios, hubo una explosión de modelos fine-tuned que mejoraban el modelo original de Meta reentrenándolo para ciertas funcionalidades específicas. Modelos como Alpaca, Vicuna o WizardLM se hicieron muy populares porque mediante un fine-tuning muy económico de Llama (<600$), ofrecían un rendimiento que se acercaba a ChatGPT, con un coste de inferencia mucho menor y con la posibilidad de correrlo a nivel local.
Esta tendencia llevó a diferentes empresas a lanzar sus propios modelos fundacionales copiando la receta de entrenamiento y arquitectura de Llama, pero ofreciendo licencias más permisivas, como es el caso de OpenLLaMA, Falcon o XGen. Aún así, con el lanzamiento de Llama 2 a mitades de 2023, el primer modelo fundacional open source capaz de competir con GPT-3.5 (con una licencia más abierta), el resto de modelos open source quedaron obsoletos. De esta manera, Llama 2 se convirtió en el modelo de facto adoptado por la comunidad open source AI con el que realizar fine tuning con datos propietarios manteniendo la privacidad.
Infraestructura y workflows en AI
Por otra parte, durante la primera mitad del 2023, el mercado de software se vio afectado por la democratización del uso de infraestructura AI gracias a la aparición de APIs con acceso a LLMs (tanto propietarios como open source) y a GPUs on-demand especializadas para correr o entrenar estos modelos. En paralelo, librerías como LangChain y LlamaIndex facilitaron la integración de estos modelos a fuentes y servicios externos expandiendo así su capacidad de desarrollo.
Durante la segunda mitad del año, el proceso de fine-tuning de estos modelos para mejorar su rendimiento en tareas específicas se convirtió en un procedimiento estándar dentro del workflow de desarrolladores LLMOps. Esta tendencia fue impulsada por varios factores: la mejora en ahorro de costes, la capacidad de procesar datos confidenciales y el potencial de desarrollar modelos que superen el rendimiento de modelos top tier como ChatGPT y GPT-4 en ciertas tareas específicas.
Esta tendencia también se vio favorecida por la popularización de herramientos y wrapers diseñados para agilizar el proceso de fine-tuning como FastChat de LMSYS (usado para entrenar Vicuna) y las librerías open source transformers/trl de Hugging Face.
En este artículo, veremos por qué funciona el fine-tuning y cómo implementarlo con Axolotl, una herramienta creada por OpenAccess AI Collective. La usaremos para hacer fine-tuning de un modelo Code Llama 7b con conjunto de datos compuesto por 1,000 ejemplos de código Python.
🔧 Intro al fine-tuning de LLMs
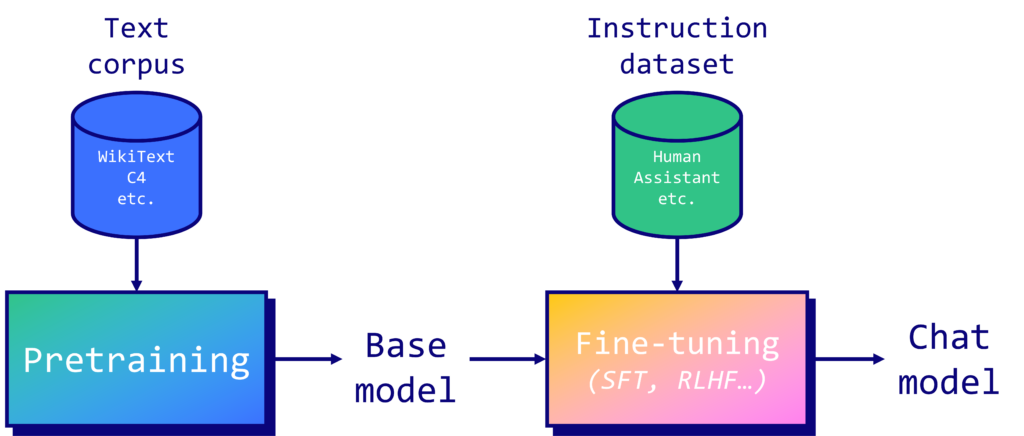
Los LLMs se pre-entrenan en un extenso corpus de texto. En el caso de Llama 2, sabemos muy poco sobre la composición del conjunto de entrenamiento, más allá de su dimensión de 2.000 millones de tokens (en inglés, un token representa de media unos 4 caracteres, pero puede variar bastante en función del tipo de modelo y texto). En comparación, BERT (2018) fue entrenado “solo” con BookCorpus (800M palabras) y Wikipedia en inglés (2,500M palabras). El pre-entreno de LLMs es un proceso muy largo y costoso con muchos retos a nivel de hardware. Si quieres saber más al respecto, te recomiendo leer el logbook de Meta sobre el preentrenamiento del modelo OPT-175B.
Cuando se completa el preentrenamiento, el modelo base obtenido puede predecir el siguiente token en una secuencia, pero no es capaz de responder a instrucciones. Por eso, si lo que queremos es un asistente que responda de la forma más humana posible o se vuelva un experto en alguna tarea específica, necesitamos emplear un tipo de fine-tuning llamado instruction tuning, tal y como hizo OpenAI para transformar el modelo base de GPT-3 en ChatGPT. Con esta técnica, se alinean las respuestas del modelo con lo que un humano u experto esperaría.
Para llevar a cabo este proceso existen dos técnicas principales:
- Supervised Fine-Tuning (SFT): Los modelos se entrenan en un conjunto de datos de instrucciones y respuestas. Se ajustan los pesos del LLM para minimizar la diferencia entre las respuestas generadas y las respuestas correctas, que actúan como etiquetas.
- Reinforcement Learning from Human Feedback (RLHF): Los modelos aprenden interactuando con su entorno y recibiendo retroalimentación. Se entrenan para maximizar una señal de recompensa (usando PPO), que a menudo se deriva de evaluaciones humanas de las repuestas generadas por el modelo.
En general, se ha demostrado que el RLHF captura preferencias humanas más complejas y matizadas, pero también es más difícil de implementar eficazmente. De hecho, requiere un diseño curado del sistema de recompensas y puede ser sensible a la calidad y consistencia de las respuestas humanas. Una alternativa posible en el futuro es el algoritmo Direct Preference Optimization (DPO), que ejecuta directamente el aprendizaje de preferencias en el modelo SFT.
¿Por qué funciona el fine-tuning?
En nuestro caso, para ver un caso práctico sencillo realizaremos un ejemplo de Supervised Fine-Tuning (SFT). Pero esto plantea una pregunta: ¿por qué funciona el fine-tuning en primer lugar? Como se destaca en el paper de Orca, un modelo propietario de Microsoft usado para estudiar este proceso, nuestro entendimiento es que el fine-tuning aprovecha el conocimiento aprendido durante el proceso de preentrenamiento de los modelos base. En otras palabras, el fine-tuning será de poca ayuda si el modelo nunca ha visto o ha visto muy poco el tipo de datos que te interesan. En caso contrario, y con un número reducido de muestras extra, el **Supervised Fine-Tuning (**SFT) puede ser extremadamente efectivo .
Por ejemplo, el paper LIMA (Less Is More for Alignment) mostró cómo se podía llegar a superar el rendimiento de ChatGPT-3.5 (DaVinci003) y BARD en un gran número de tareas con un simple fine-tuning de LLaMA (v1) usando 1,000 muestras de alta calidad. La calidad del conjunto de datos de instrucción es esencial para alcanzar este nivel de rendimiento. Por esta razón, hay bastante investigación enfocada en desarrollar técnicas para mejorar la calidad de estos datos; proyectos como evol-instruct, Orca o phi-1, buscan introducir nuevas metodologías y marcos de trabajo para mejorar los datos de instrucción. También hay que tener en cuenta que el tamaño del LLM (65b, no 13b o 7b) será fundamental para aprovechar eficientemente el conocimiento preexistente.
Otro punto importante relacionado con la calidad de los datos es la plantilla o prompt de reentrenamiento que se usa para el fine-tuning. Una plantilla bien diseñada optimiza el rendimiento del modelo al dirigir el aprendizaje hacia los objetivos deseados. También mejora la interacción usuario-modelo al establecer un formato de comunicación claro y predecible. Esto resulta en un modelo más intuitivo y efectivo, capaz de generar respuestas relevantes y contextualmente adecuadas.
Como ejemplo de plantilla veamos el caso de Llama 2, donde los autores usaron la siguiente plantilla para los modelos de chat (Llama Chat):
<s>[INST] <<SYS>>
System prompt //Prompt del sistema (opcional) para guiar al modelo
<</SYS>>
User prompt [/INST] //Prompt del usuario (obligatorio) para dar la instrucción
Model answer </s> //Respuesta del modelo (obligatoria)
Manos a la obra
En este ejemplo, vamos a realizar un fine-tuning de un modelo Code Llama 7b con un conjunto de datos compuesto por 1,000 ejemplos de código Python. Para hacerlo, utilizaremos una herramienta open source llamada Axolotl.
🤔¿Por qué Axolotl?
El principal atractivo de Axolotl es que ofrece una solución one-stop que incluye numerosas técnicas de entrenamiento SOTA, arquitecturas de modelo y numerosas utilidades user-friendly integradas, como una configuración personalizada de Weight&Biases. Dispone también de una comunidad muy activa y cada vez está siendo más adoptada por la comunidad open source.
⚙️ Crea tu propio archivo de configuración
El primer paso en este ejemplo, sería crear un archivo de configuración donde definimos los distintos parámetros y valores que vamos a usar en el entrenamiento. Este paso es un poco técnico, y requiere entender ciertos conceptos previos, así que partiremos de un archivo ya configurado y profundizaremos en ello en un futuro blog.
Este archivo de configuración es una adaptación de la configuración de Llama 2 que usaremos para crear nuestro propio modelo Code Llama. El modelo se entrenará con el siguiente conjunto de datos mlabonne/Evol-Instruct-Python-1k, que consta de 1,000 ejemplos de código en Python.
🦙 Fine tuning de Code Llama
Una vez que el archivo de configuración está listo, es hora de ponernos manos a la obra con el fine tuning propiamente dicho. Una opción sería ejecutar el entrenamiento en un notebook de Colab. Sin embargo, para aquellos sin acceso a una GPU de alto rendimiento, una solución más rentable es alquilar servicios de GPU cloud especializados en AI como Together.ai (visto en el último artículo), Lambda Labs, Vast.ai, Banana o RunPod.
En este caso, en vez de usar Together como hicimos en el último artículo, usaremos RunPod, que es una opción popular en la comunidad de fine tuning. No es el servicio más barato, pero ofrece un buen equilibrio entre precio y rendimiento y tiene una interfaz de usuario muy intuitiva. Puedes replicar fácilmente los siguientes pasos usando tu servicio favorito.
Una vez configurada tu cuenta de RunPod, ve a Manage > Templates y haz clic en “New Template”. Aquí tienes una plantilla simple que puedes copiar añadiendo tu API key de WandB para hacer un seguimiento del entrenamiento:
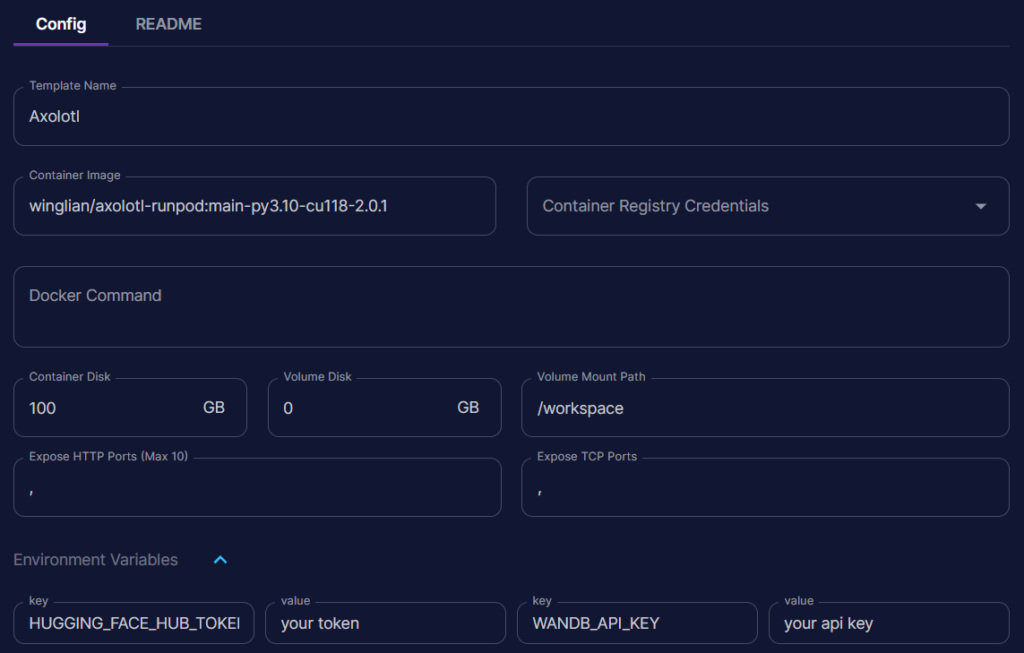
Una vez configurado, puedes ir a Community Cloud y desplegar la GPU que vamos a usar para el entrenamiento. En nuestro caso, y por el tipo sencillo de fine tuning que vamos a realizar, con una RTX 3090 será suficiente. Si los precios no han cambiado, el coste de uso de esta GPU es de $0.34/hr, y como veremos luego, el tiempo de entrenamiento no superará las dos horas, es decir, el fine tuning completo nos costará menos de $1.
Para desplegar la GPU, simplemente busca el nombre del Template que hemos generado previamente y selecciónalo como vemos a continuación:

Puedes hacer clic en “Continue” y RunPod desplegará tu template. Podrás ver la instalación en los registros de tu pod. Cuando la opción esté disponible, haz clic en “Connect”. Aquí, haz clic en “Start Web Terminal” y luego “Connect to Web Terminal”. ¡Ya estás conectado a tu pod!
Los siguientes pasos a realizar en tu terminal son los mismos sin importar si usas RunPod o algún otro servicio GPU en el cloud:
- Instalamos Axolotl y la biblioteca PEFT de la siguiente manera:
git clone <https://github.com/OpenAccess-AI-Collective/axolotl>
cd axolotl
pip3 install -e .[flash-attn]
pip3 install -U git+https://github.com/huggingface/peft.git
2. Descarga el archivo de configuración que creamos:
wget <https://gist.githubusercontent.com/mlabonne/8055f6335e2b85f082c8c75561321a66/raw/93915a9563fcfff8df9a81fc0cdbf63894465922/EvolCodeLlama-7b.yaml>
3. Ahora puedes comenzar a hacer fine tuning del modelo con el siguiente comando:
accelerate launch scripts/finetune.py EvolCodeLlama-7b.yaml
Si todo está configurado correctamente, deberías poder entrenar el modelo en poco más de una hora (a mi me tardó 1h 13m). Si revisas la memoria GPU utilizada, verás que se usa el 100% con esta configuración, lo que significa que la estamos optimizando bastante bien. Si estás usando una GPU con más VRAM (como una A100), puedes aumentar el tamaño del micro-batch de datos de entrenamiento para asegurarte de que estás usándola al máximo de su rendimiento.
Mientras tanto, puedes cerrar la terminal web y revisar tu entrenamiento en Weights & Biases. Estamos usando tmux, así que el entrenamiento no se parará si cierras la terminal. Aquí están mis curvas de entrenamiento:
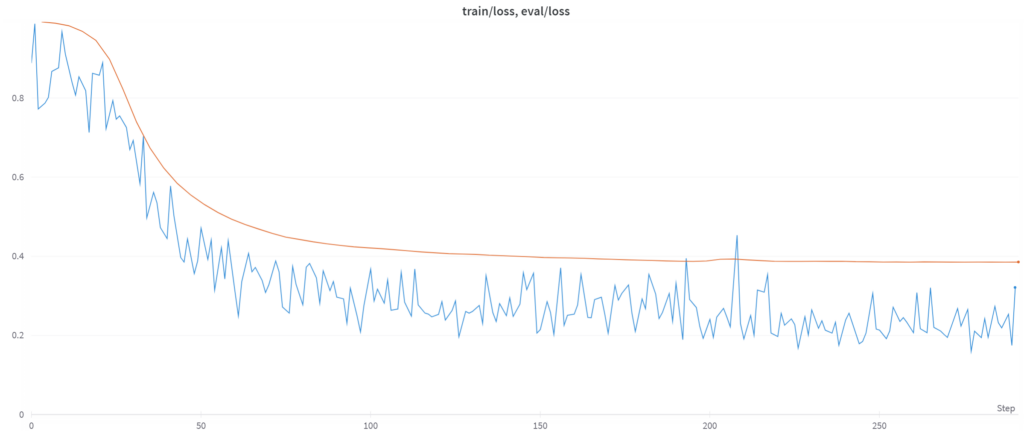
Vemos una mejora constante en la eval loss, lo cual es buena señal. Sin embargo, también puedes notar caídas en la eval loss que no están correlacionadas con una disminución en la calidad de los outputs. La mejor manera de evaluar tu modelo es simplemente usándolo: puedes ejecutarlo en la terminal con el comando: accelerate launch scripts/finetune.py EvolCodeLlama-7b.yaml –inference –lora_model_dir="./qlora-out".
Considerando que es un LLM de código, sería interesante comparar su rendimiento con otros modelos en benchmarks estándar, como HumanEval y MBPP. Como referencia, puedes encontrar una tabla de clasificación en la siguiente dirección: Multilingual Code Evals.
Llegados a este punto solo no quedaría fusionar los pesos del modelo base y el fine-tuned y subir nuestro modelo fine-tuned EvolCodeLlama-7b a Hugging Face Hub!
Conclusión
En este artículo, hemos cubierto lo esencial sobre cómo realizar un fine-tuning de LLMs de manera eficiente. Hemos empezado con un pequeño conjunto de datos de Python, a continuación hemos definido los parámetros necesarios para entrenar nuestro modelo Code Llama, hemos realizado el entrenamiento con Axolotl via RunPod y por último simplemente nos quedaría fusionar los pesos de los modelos y subir el resultado a Hugging Face.
Espero haya sido un artículo interesante. Como próximos pasos, algo que considero útil y me ha servido a mi, es seguir haciendo pruebas o pequeños experimentos con Axolotl o algún otro servicio de GPU basado en el cloud para ganar algo de experiencia y subir algunos modelos a Hugging Face. Puedes construir tus propios conjuntos de datos, jugar con los parámetros y testear nuevos modelos open source, todo sin tener que dedicar mucho tiempo.
Y por último, como con cualquier wrapper, no dudes en revisar el código fuente para tener una buena intuición de lo que realmente está haciendo el modelo base. Aparte de hacerlo por mera curiosidad, entender algo de lo que hace nos puede ayudar a largo plazo. Nos centraremos más en ello en futuros artículos 😉


