El 30 de noviembre de 2022, OpenAI lanzó ChatGPT, colocando los Large Language Models (LLMs) en el centro de atención.
LangChain apareció aproximadamente en el mismo momento. Su creador, Harrison Chase, realizó el primer commit a finales de octubre de 2022, y el proyecto solo tardó un par de meses en despegar y ser atrapado por la ola de los LLMs.
A pesar de encontrarse aún en sus primeros días, esta librería ya está repleta de características muy interesantes para construir herramientas alrededor del núcleo de los LLMs. Y para empezar a trabajar con LangChain no hace falta más que descargarse la librería con un simple comando de Python, lo que la convierte en una colección de recursos ideal que facilita mucho la creación de aplicaciones con LLMs.
En este artículo, presentaremos la librería y comenzaremos a utilizar el componente más sencillo ofrecido por LangChain: los LLMs.
¿Qué es LangChain?
En esencia, Langchain es una librería que permite construir aplicaciones con LLMs como GPT-4. Podemos utilizarlo para crear chatbots, Generative Question-Answering (GQA), resúmenes, y mucho más.
Usar un LLM de forma aislada está bien para aplicaciones simples, pero las aplicaciones más complejas requieren encadenar LLMs – ya sea entre ellos o con otros componentes. LangChain proporciona la interfaz Chain para construir estas aplicaciones “encadenadas”.
Chains
Definimos una Chain de manera muy genérica como una secuencia de llamadas a componentes, que pueden incluir otras chains.
Esta idea de unir varios componentes juntos en una chain es simple pero poderosa. Simplifica drásticamente y hace más modular la implementación de aplicaciones complejas, lo que a su vez facilita mucho depurar, mantener y mejorar tus aplicaciones.
Las cadenas pueden consistir en múltiples componentes de varios módulos:
- Prompt templates: Los prompt templates son plantillas para crear diferentes tipos de prompts, como plantillas de estilo “chatbot”, question-answering, etc.
- LLMs: Large Language Models como GPT-3, BLOOM, etc.
- Agents: La idea central de los agents es utilizar un LLM para elegir una secuencia de acciones a realizar. Cuando creamos una chain, podemos definir una secuencia de acciones que estén hardcoded (ya prefijadas), o podemos usar agents, que utilizan un modelo de lenguaje como motor de razonamiento para determinar qué acciones tomar y en qué orden.
- Memory: Es la capacidad de almacenar información sobre interacciones pasadas. Recordemos que cada chain define una lógica de ejecución que depende de inputs; y mientras que algunos de estos inputs provienen directamente del usuario, otros pueden provenir de chains anteriores. La propia estructura de encadenamiento es lo que permite dotar de memoria al sistema y a los agents.
- Retrieval: Muchas aplicaciones con LLMs requieren datos específicos del usuario que no forman parte del conjunto de entrenamiento del modelo. Por ejemplo, cuando un modelo está entrenado con datos públicos pero queremos que los resultados que obtengamos tengan en cuenta datos internos privados. La principal manera de lograr esto es a través de la Retrieval Augmented Generation (RAG). En este proceso, se accede a datos externos al conjunto de entrenamiento, ya sea en formato texto, data estructurada de APIs o código, y luego se pasan al LLM durante la etapa de generación. LangChain proporciona todos los bloques de construcción para aplicaciones RAG.
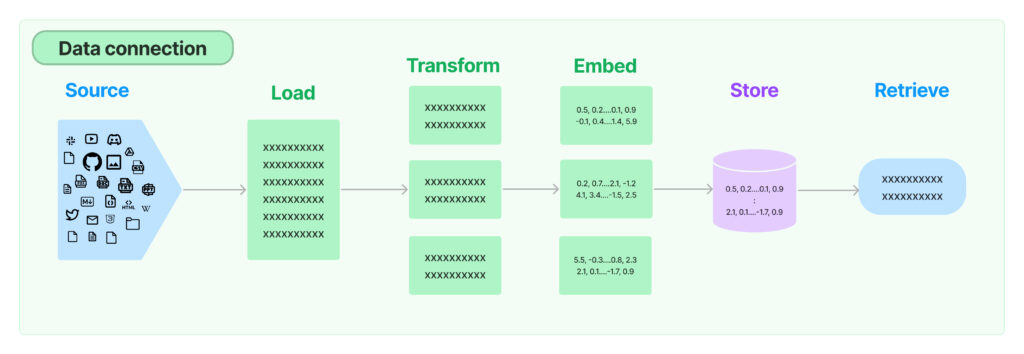
Profundizaremos en cada uno de estos temas en más detalle en blogs posteriores.
Ejemplos
Ahora, para tener una visión más aterrizada, veamos una serie de ejemplos de soluciones que podríamos construir (y ya se han construido) con LangChain:
Soluciones para programadores. Por ejemplo, es posible crear un aplicación para el Command Line Interface (CLI) que te genera automáticamente un archivo README basado en el código fuente del proyecto; o una aplicación que explica en lenguaje natural el código de un archivo dado.
Otro ejemplo típico sería una aplicación que te permite hacer preguntas en lenguaje natural sobre tus documentos privados, como PrivateGPT; o una aplicación que dibuja diagramas o mapas mentales a partir de descripciones.
A nivel de código y datos estructurados, podríamos construir una aplicación que realiza queries a bases de datos para obtener información, aprovechando la librería SQLAlchemy, y luego procesa estos datos con un LLM.
O un agente que puede resolver rompecabezas matemáticos y de razonamiento específicos utilizando LLMMathChain, una chain que interpreta un prompt y ejecuta código Python para hacer matemáticas.
O simplemente, si queremos mejorar nuestra productividad, podríamos construir una aplicación que se conecta a nuestro email para procesarlo y luego categorizarlo.
Entraremos ahora en conceptos más específicos y mostraremos con ejemplos lo fácil que es empezar a utilizar los recursos de LangChain. Comenzaremos con conceptos básicos relacionados con los prompt templates y los LLMs. También exploraremos dos opciones de LLM disponibles en la librería de LangChain, utilizando modelos de Hugging Face Hub o OpenAI.
Primeros Prompt Templates
Para adaptar su uso, los prompts que introduce el usuario se transforman y estructuran antes de enviarse al LLM, en función del tipo de aplicación o caso de uso. Por ejemplo para Q&A, podríamos tomar una pregunta del usuario y reformatearla para diferentes estilos de Q&A, como Q&A convencional o para obtener una lista de respuestas o incluso un resumen de problemas relevantes para la pregunta dada.
Creando Prompts en LangChain
Vamos a construir un prompt template simple para question-answering. Trabajaremos todo el rato en el entorno de Jupyter Notebook, que podemos ejecutar localmente o usar en Google Colab. Primero necesitamos instalar la librería langchain:
!pip install langchainDesde aquí, importamos la clase PromptTemplate e inicializamos una template así:
from langchain import PromptTemplate
template = """Pregunta: {question}
Respuesta: """
prompt = PromptTemplate(
template=template,
input_variables=['question']
)
#pregunta del usuario
question = "¿Qué equipo de la NFL ganó la Super Bowl en la temporada 2010?"Al usar este prompt template con la question dada, estamos definiendo el formato con el que se estructura y muestra la información, y obtendremos:
Pregunta: ¿Qué equipo de la NFL ganó Super Bowl en la temporada 2010?
Respuesta:
Por ahora, eso es todo lo que necesitamos. Utilizaremos el mismo prompt template en las generaciones de LLM tanto en Hugging Face Hub como con OpenAI.
Hugging Face Hub LLM
El API endpoint de Hugging Face en LangChain se conecta con Hugging Face Hub y ejecuta los modelos a través de sus endpoint de inferencia gratuitos. Necesitamos una cuenta de Hugging Face y una clave API para usar estos endpoints.
Una vez tengas la clave API, la agregamos a la variable de entorno HUGGINGFACEHUB_API_TOKEN. Podemos hacer esto con Python de la siguiente manera:
import os
os.environ['HUGGINGFACEHUB_API_TOKEN'] = 'HF_API_KEY'A continuación, debemos instalar la librería huggingface_hub a través de Pip.
!pip install huggingface_hubAhora podemos generar texto utilizando un modelo del Hub. Usaremos google/flan-t5-x1.
Las inference APIs predeterminadas de Hugging Face Hub no utilizan hardware especializado y, por lo tanto, pueden ser lentas. Y por ende, tampoco son adecuadas para ejecutar modelos más grandes como bigscience/bloom-560m.
In[3]:
from langchain import HuggingFaceHub, LLMChain
# inizializar el LLM de Hub
hub_llm = HuggingFaceHub(
repo_id='google/flan-t5-xl',
model_kwargs={'temperature':1e-10}
)
# crear prompt template > LLM chain (encadenamos)
llm_chain = LLMChain(
prompt=prompt,
llm=hub_llm
)
# preguntar al usuario la pregunta
print(llm_chain.run(question))
Out[3]:
green bay packersPara esta pregunta, obtenemos la respuesta correcta “green bay packers”
Haciendo Múltiples Preguntas
Si quisiéramos hacer múltiples preguntas, podríamos probar dos enfoques para pasárselas al LLM:
- Iterar a través de todas las preguntas usando el método generate, respondiéndolas una por una.
- Colocar todas las preguntas en un solo prompt para el LLM; esto solo funcionará para los LLMs más avanzados.
Comenzando con la opción (1), veamos cómo usar el método generate:
In[4]:
qs = [
{'question': "¿Qué equipo de la NFL ganó el Super Bowl en la temporada 2010?"},
{'question': "Si mido 6 pies 4 pulgadas, ¿cuánto es en centímetros?"},
{'question': "¿Quién fue la duodécima persona en la luna?"},
{'question': "¿Cuántos ojos tiene una hoja de césped?"}
]
res = llm_chain.generate(qs)
res
Out[4]:
LLMResult(generations=[[Generation(text='green bay packers', generation_info=None)],\
[Generation(text='184', generation_info=None)],\
[Generation(text='john glenn', generation_info=None)],\
[Generation(text='one', generation_info=None)]], llm_output=None)El código anterior genera preguntas y obtiene las respuestas correspondientes utilizando el método generate del objeto LLMChain. La lista qs contiene diccionarios con la clave “question” y la pregunta correspondiente como valor. El resultado se almacena en la variable res.
Aquí obtenemos malos resultados excepto para la primera pregunta. Esto es simplemente una limitación del LLM utilizado.
Si el modelo no puede responder preguntas individuales con precisión, agrupar todas las consultas en un solo prompt probablemente no funcione. Sin embargo, por el bien del experimento, intentémoslo.
In[6]:
multi_template = """Responde las siguientes preguntas una a una.
Preguntas:
{questions}
Respuestas:
"""
long_prompt = PromptTemplate(template=multi_template, input_variables=["questions"])
llm_chain = LLMChain(
prompt=long_prompt,
llm=flan_t5
)
qs_str = (
"¿Qué equipo de la NFL ganó el Super Bowl en la temporada 2010?\\\\n" +
"Si mido 6 pies 4 pulgadas, ¿cuánto es en centímetros?\\\\n" +
"¿Quién fue la duodécima persona en la luna?" +
"¿Cuántos ojos tiene una hoja de césped?"
)
print(llm_chain.run(qs_str))
Out[6]:
Si mido 6 pies 4 pulgadas, ¿cuánto es en centímetros?Como esperábamos, los resultados no son muy esperanzadores. Aún así luego veremos que LLMs más potentes pueden realizar sin problemas esta tarea.
LLMs de OpenAI
Los endpoits de OpenAI en LangChain se conectan directamente con OpenAI o a través de Azure. Necesitamos una cuenta de OpenAI y una clave API para usar estos endpoints.
Una vez tengamos una clave API, la agregamos a la variable de entorno OPENAI_API_TOKEN. Podemos hacer esto con Python de la siguiente manera:
import os
os.environ['OPENAI_API_TOKEN'] = 'OPENAI_API_KEY'A continuación, debemos instalar la librería openai via Pip.
!pip install openaiAhora podemos generar texto usando los modelos GPT-3 de OpenAI. Usaremos text-davinci-003.
from langchain.llms import OpenAI
davinci = OpenAI(model_name='text-davinci-003')Alternativamente, si estás utilizando OpenAI a través de Azure, puedes hacer:
from langchain.llms import AzureOpenAI
llm = AzureOpenAI(
deployment_name="tu-despliegue-en-azure",
model_name="text-davinci-003"
)Usaremos el mismo prompt template simple de question-answer que antes con el ejemplo de Hugging Face. El único cambio es que ahora usaremos el LLM davinci de OpenAI:
In[15]:
llm_chain = LLMChain(
prompt=prompt,
llm=davinci
)
print(llm_chain.run(question))
Out[15]:
Los Green Bay Packers ganaron el Super Bowl en la temporada 2010.Como se esperaba, estamos obteniendo la respuesta correcta. Podemos hacer lo mismo para múltiples preguntas usando generate:
In[16]:
qs = [
{'question': "¿Qué equipo de la NFL ganó el Super Bowl en la temporada 2010?"},
{'question': "Si mido 6 pies 4 pulgadas, ¿cuánto es en centímetros?"},
{'question': "¿Quién fue la duodécima persona en la luna?"},
{'question': "¿Cuántos ojos tiene una hoja de césped?"}
]
llm_chain.generate(qs)
Out[16]:
LLMResult(generations=[
[Generation(text=' Los Green Bay Packers ganaron el Super Bowl en la temporada 2010.',\
generation_info={'finish_reason': 'stop', 'logprobs': None})],
[Generation(text=' 193.04 centímetros', generation_info={'finish_reason': 'stop', 'logprobs': None})],
[Generation(text=' Charles Duke fue la duodécima persona en la luna. Formó parte de la misión Apollo 16 en 1972.',\
generation_info={'finish_reason': 'stop', 'logprobs': None})],
[Generation(text=' Una hoja de césped no tiene ojos.',\
generation_info={'finish_reason': 'stop', 'logprobs': None})]],
llm_output={'token_usage': {'total_tokens': 124, 'prompt_tokens': 75, 'completion_tokens': 49}})Observamos que todas las respuestas son correctas. El modelo funciona claramente mejor que el modelo google/flan-t5-xl. Ahora, como hemos hecho antes, intentemos introducir todas las preguntas a la vez en el modelo .
In[17]:
llm_chain = LLMChain(
prompt=long_prompt,
llm=davinci
)
qs_str = (
"¿Qué equipo de la NFL ganó el Super Bowl en la temporada 2010?\\n" +
"Si mido 6 pies 4 pulgadas, ¿cuánto es en centímetros?\\n" +
"¿Quién fue la duodécima persona en la luna?" +
"¿Cuántos ojos tiene una hoja de césped?"
)
print(llm_chain.run(qs_str))
Out[17]:
Los New Orleans Saints ganaron el Super Bowl en la temporada 2010.
6 pies 4 pulgadas son 193 centímetros.
La duodécima persona en la luna fue Harrison Schmitt.
Una hoja de césped no tiene ojos.Observamos que no todas las respuestas con correctas pero se acerca bastante. Si vamos re-ejecutando el prompt, el modelo ocasionalmente cometerá errores, pero en otras ocasiones logrará obtener todas las respuestas correctas.


