Introducción
En los últimos años, el procesamiento del lenguaje natural (NLP) ha experimentado un avance significativo gracias a una técnica llamada “word embeddings”. Estos embeddings transforman las palabras en vectores numéricos, permitiendo que los algoritmos de aprendizaje automático las procesen de manera eficiente. En este artículo, exploraremos en profundidad los word embeddings, discutiremos sus fundamentos, sus variaciones y cómo se utilizan en la práctica.
La esencia de los Word Embeddings
Los word embeddings son representaciones vectoriales de palabras en un espacio multidimensional. Cada palabra se traduce en un vector, y la posición de cada palabra en este espacio (o “embedding”) se determina por el contexto en el que aparece en los textos de entrenamiento. Así, palabras con significados similares tendrán vectores cercanos en este espacio.
Un ejemplo simplificado puede ayudar a ilustrar esto. Imagina un espacio de embeddings de tres dimensiones donde cada eje representa un color primario: rojo, verde y azul. La palabra “cielo” podría representarse como el vector (0, 0, 1) porque está asociada con el color azul. En cambio, “hierba” podría representarse como (0, 1, 0) porque está asociada con el color verde.
Veamos otro ejemplo. Entrenamos un modelo de embedding de 4 dimensiones con un corpus de texto donde aparecen las palabras perro y gato. Si el modelo es capaz de preservar la similitud contextual, entonces ambas palabras estarán representadas con vectores próximos:
W(cat) = (0.9, 0.1, 0.3, -0.23)
W(dog) = (0.76, 0.1, -0.38, 0.3)
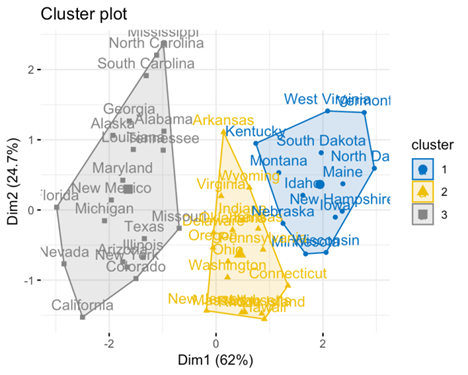
¿Y si hay más palabras? El trabajo de un modelo de embedding es agrupar información similar y establecer una relación entre ellos en función del contexto. Podemos ver un ejemplo de agrupación de palabras a partir de la proximidad de su significado dentro de un cuerpo amplio de texto:
En un ejemplo más realista y complejo, la palabra “rey” podría estar representada por un vector de 300 dimensiones con valores en cada dimensión que se aprenden a partir de los datos. Los valores exactos en cada dimensión son menos importantes que las distancias y direcciones entre diferentes vectores de palabras en este espacio n-dimensional. Por ejemplo, la operación “rey” – “hombre” + “mujer” podría resultar en un vector que está muy cerca del vector “reina”, ya que los pares rey-hombre y reina-mujer están relacionados por el género, y esta es una característica plasmada en una misma dimensión de los vectores; y cuando hacemos la operación vectorial “rey”-“hombre”, estamos restando la componente hombre de rey, pero mantenemos el componente realeza.
Inicios
El concepto de word embeddings en el procesamiento del lenguaje natural fue introducido por un equipo liderado por Yoshua Bengio a principios de la década de 2000. Su trabajo pionero se cita a menudo en dos papers clave: “A Neural Probabilistic Language Model” publicado en 2001, y “A Neural Network Architecture for Factored Language Modeling” publicado en 2003. Presentaron un nuevo enfoque para el modelado estadístico del lenguaje que utilizaba una red neuronal y aprendía representaciones distribuidas para las palabras, ahora comúnmente referidas como word embeddings.
Su modelo fue diseñado para abordar un problema clave en el modelado del lenguaje, conocido como la maldición de la dimensionalidad. Esto se refiere a la dificultad de modelar eficientemente el lenguaje por tener que considerar todas las posibles combinaciones de palabras y frases. Los modelos de lenguaje tradicionales, como los modelos n-gram, luchan con este problema ya que crecen exponencialmente con el número de palabras consideradas. Además, no existía una medida de proximidad de significado entre palabras y frases, lo que llevaba a problemas de dispersión de datos.
El modelo de Bengio, en contraste, aprendió una representación distribuida para las palabras, lo que efectivamente significaba que cada palabra era representada por un vector denso (el “embedding”) de números reales. Los valores en estos vectores se aprendieron de manera que palabras similares tenían vectores similares, lo que significa que compartían fuerza estadística.
Funcionamiento del modelo de Bengio
- Representación de palabras: Cada palabra en el vocabulario del modelo se representa como un vector de características (word embedding; cada dimensión del vector corresponde a una carectaerística). Estos vectores son parte de los parámetros del modelo y se aprenden durante el entrenamiento. La intuición es que las palabras similares tendrán vectores de características similares.
- Representación de contexto: Dada una secuencia de palabras, el modelo concatena los vectores de características de las palabras anteriores para formar un vector de contexto. Por ejemplo, si el modelo intenta predecir la próxima palabra dada la secuencia “el gato está en el”, los vectores de características para “el”, “gato”, “está”, “en” se sumarían vectorialmente para formar el vector de contexto.
- Predicción con Red Neuronal Feedforward: Este vector de contexto se pasa entonces a través de una red neuronal feedforward (una capa oculta seguida de una capa de salida softmax). La capa oculta permite tener un modelo no lineal. La capa de salida softmax calcula la distribución de probabilidad sobre todas las posibles palabras del vocabulario que pueden ser la continuación del vector de contexto. La palabra con la mayor probabilidad suele ser elegida como la predicción.
- Entrenamiento: El modelo se entrena con un gran corpus de texto. El objetivo es ajustar los parámetros del modelo (los vectores de características de las palabras y los pesos de la red neuronal) para maximizar la verosimilitud de los datos de entrenamiento. Esto se hace normalmente utilizando el descenso de gradiente estocástico y el método de backpropagation.
- Generación de texto: Una vez que el modelo está entrenado, puede generar nuevo texto muestreando palabras de las distribuciones de probabilidad calculadas.
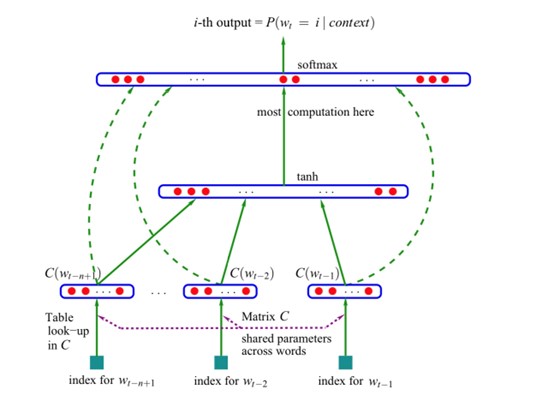
Este enfoque fue innovador para su tiempo, ya que permitió al modelo generalizar desde las secuencias de palabras vistas a las secuencias de palabras no vistas, gracias a los vectores de características de palabras. Sin embargo, fue computacionalmente costoso debido al uso de una capa de salida softmax sobre vocabularios grandes.
Word2Vec
Aunque el trabajo del equipo de Bengio sentó las bases para los word embeddings, no fue hasta 2013 con la introducción de Word2Vec por un equipo de Google, liderado por Tomas Mikolov, que el uso de word embeddings se generalizó. Word2Vec es un método para crear eficientemente word embeddings y hace ciertas asunciones sobre los datos del lenguaje que le permiten aprender embeddings de alta calidad más rápidamente que con los métodos anteriores.
Arquitectura del modelo: Word2Vec proporciona dos arquitecturas que se usan de forma complementaria para entrenar el modelo: Continuous Bag of Words (CBOW) y Skip-Gram. En CBOW, el modelo predice la palabra actual en función de su contexto. En Skip-Gram, el modelo predice las palabras de contexto dado la palabra actual. A diferencia del modelo de Bengio, el contexto de Word2Vec no se limita solo a las palabras precedentes. La ventana de contexto puede deslizarse sobre el texto.
Entrenamiento: Word2Vec se entrena para maximizar la verosimilitud del contexto dada una palabra (Skip-Gram) o de una palabra dado su contexto (CBOW). Introduce varias técnicas de optimización como softmax jerárquico y muestreo negativo para mejorar la eficiencia computacional.
Ventajas: Word2Vec es computacionalmente más eficiente que el modelo de Bengio debido a su arquitectura simplificada y optimizaciones en la fase de entrenamiento. Es capaz de capturar una amplia gama de relaciones semánticas y sintácticas de palabras.
Nuevos modelos
En 2014, el modelo GloVe (Global Vectors for Word Representation), desarrollado por Jeffrey Pennington en la Universidad de Stanford, se presentó como otro método para crear word embeddings. GloVe se basa en la idea de matrices de co-ocurrencia para generar embeddings de una forma similar a como se hace en el análisis de imágenes con las matrices de co-ocurrencia del nivel de gris (GLCM), que realizan un resumen de la forma en que los valores de los pixeles ocurren al lado de otro valor en una pequeña ventana.
Luego llegó fastText, introducido por el laboratorio de Investigación en Inteligencia Artificial de Facebook (FAIR) en 2016. A diferencia de Word2Vec y GloVe, que trabajan con tokens de palabras, fastText trata cada palabra como compuesta por n-gramas de caracteres. Esto le permite generar mejores representaciones para los idiomas ricos en morfología como el finlandés o el japonés, y también manejar palabras que no están en el vocabulario.
Mientras que todos estos modelos comparten el objetivo común de aprender representaciones distribuidas de palabras, cada modelo tiene sus características y fortalezas únicas. El trabajo pionero de Bengio sentó las bases para los modelos de lenguaje neuronal, Word2Vec mejoró la eficiencia y la calidad de los embeddings, GloVe capturó tanto las estadísticas globales como locales, y fastText añadió la capacidad de manejar ricas morfologías y palabras fuera del vocabulario. Estos modelos supusieron una revolución en su momento, pero se han vuelto obsoletos con algunos modelos nuevos como SBERT o el nuevo modelo text-embedding-ada-002 de OpenAI, que presentan mejores resultados a un menor coste de computación.
Aplicaciones
Estos embeddings se pueden utilizar como características input para muchas tareas de NLP, como análisis de sentimientos, traducción automática, reconocimiento de entidades con nombre, etc.
Los embeddings tienen distintas aplicaciones. Una de las más comunes y por la cual se ha vuelto tan importante dentro del campo del Deep Learning, es la capacidad de entrenar grandes modelos de NLP usando los embeddings como un input cuantitativo a predecir, es decir, el texto del dataset de entreno se mapea primero a un espacio vectorial. Se pueden usar los embeddings para entrenar un modelo desde cero en tareas como análisis de sentimientos, traducción automática o reconocimiento, y también para realizar un fine-tunning de forma eficiente.
Pero el otro caso de uso principal es usar el modelo de embeddings directamente para realizar tareas de búsqueda de texto, análisis de similitud de textos y búsqueda de código. En estos casos, lo más común era adaptar el tipo de embedding en función de la tarea de búsqueda o similitud que se quería realizar. Pero nuevos modelos de embbedings, como el text-embedding-ada-002 de OpenAI (Dec. 2022), han conseguido unificar las distintas capacidades de búsqueda y ofrecer mejor rendimiento pese a la reducción del tamaño de los embeddings. Estas nuevas funcionalidades han permitido que los modelos de embedding se hayan vuelto muy útiles en casos de uso real, y hayan sido adoptados rápidamente por aplicaciones como Notion o herramientas similares de gestión de conocimiento, ya que añaden la capacidad de poder asociar ideas, conceptos y contactos con algún punto en común dentro de tu base de datos personal.


